El estado de Oaxaca de Juárez esta compuesto por 570 municipios y de ellos 457 tiene nombres de santos.


 El contraste de rachas permite verificar la hipótesis nula de que la muestra es aleatoria, es decir, si las sucesivas observaciones son independientes. Este contraste se basa en el número de rachas que presenta una muestra. Una racha se define como una secuencia de valores muestrales con una característica común precedida y seguida por valores que no presentan esa característica. Así, se considera una racha la secuencia de k valores consecutivos superiores o iguales a la media muestral (o a la mediana o a la moda, o a cualquier otro valor de corte) siempre que estén precedidos y seguidos por valores inferiores a la media muestral (o a la mediana o a la moda, o a cualquier otro valor de corte).
El contraste de rachas permite verificar la hipótesis nula de que la muestra es aleatoria, es decir, si las sucesivas observaciones son independientes. Este contraste se basa en el número de rachas que presenta una muestra. Una racha se define como una secuencia de valores muestrales con una característica común precedida y seguida por valores que no presentan esa característica. Así, se considera una racha la secuencia de k valores consecutivos superiores o iguales a la media muestral (o a la mediana o a la moda, o a cualquier otro valor de corte) siempre que estén precedidos y seguidos por valores inferiores a la media muestral (o a la mediana o a la moda, o a cualquier otro valor de corte). Se utiliza cuando la variable subyacente es continua pero presupone ningún tipo de distribución particular.
Se utiliza cuando la variable subyacente es continua pero presupone ningún tipo de distribución particular. . El objetivo del test es comprobar si puede dictaminarse que los valores
. El objetivo del test es comprobar si puede dictaminarse que los valores  e
e  son o no iguales.
son o no iguales. , entonces los valores
, entonces los valores  son independientes. tienen una misma distribución continua y simétrica respecto a una mediana común
son independientes. tienen una misma distribución continua y simétrica respecto a una mediana común 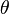 .
. :
:  . Retrotrayendo dicha hipótesis a los valores
. Retrotrayendo dicha hipótesis a los valores  originales, ésta vendría a decir que son en cierto sentido del mismo tamaño.
originales, ésta vendría a decir que son en cierto sentido del mismo tamaño. y se les asigna su rango
y se les asigna su rango  . Entonces, el estadístico de la prueba de los signos de Wilcoxon,
. Entonces, el estadístico de la prueba de los signos de Wilcoxon,  , es
, es correspondientes a los valores positivos de . puede consultarse en tablas para determinar si se acepta o no la hipótesis nula.
correspondientes a los valores positivos de . puede consultarse en tablas para determinar si se acepta o no la hipótesis nula.


 donde n1 y n2 son los tamaños respectivos de cada muestra; R1 y R2 es la suma de los rangos de las observaciones de las muestras 1 y 2 respectivamente.
donde n1 y n2 son los tamaños respectivos de cada muestra; R1 y R2 es la suma de los rangos de las observaciones de las muestras 1 y 2 respectivamente.


 Variables cualitativas
Variables cualitativas Variable cualitativa nominal: En esta variable los valores no pueden ser sometidos a un criterio de orden como por ejemplo los colores o el lugar de residencia.
Variable cualitativa nominal: En esta variable los valores no pueden ser sometidos a un criterio de orden como por ejemplo los colores o el lugar de residencia. 
A=0
|
A=1
|
Total
| |
B=0
|
A
|
b
|
a+b
|
B=1
|
C
|
d
|
c+d
|
Total
|
a+c
|
b+d
|
a+b+c+d
|

 Una variable ordinal es definida simplemente como un conjunto de categorías mutuamente excluyentes que están ordenadas en términos de la característica de interés. Aunque son posibles varios refinamientos a la medición ordinal, tales como asignar rangos a distancias entre varias categorías así como a las propias categorías, tales complicaciones no se considerarán aquí. Ocasionalmente, será útil asignar nombres numéricos a las categorías de una variable ordinal tales como (1) alto, (2) medio, (3) bajo.
Una variable ordinal es definida simplemente como un conjunto de categorías mutuamente excluyentes que están ordenadas en términos de la característica de interés. Aunque son posibles varios refinamientos a la medición ordinal, tales como asignar rangos a distancias entre varias categorías así como a las propias categorías, tales complicaciones no se considerarán aquí. Ocasionalmente, será útil asignar nombres numéricos a las categorías de una variable ordinal tales como (1) alto, (2) medio, (3) bajo.
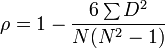


 El coeficiente de correlación de Pearson es un índice que mide la relación lineal entre dos variables aleatorias cuantitativas. A diferencia de la covarianza, la correlación de Pearson es independiente de la escala de medida de las variables.
El coeficiente de correlación de Pearson es un índice que mide la relación lineal entre dos variables aleatorias cuantitativas. A diferencia de la covarianza, la correlación de Pearson es independiente de la escala de medida de las variables.
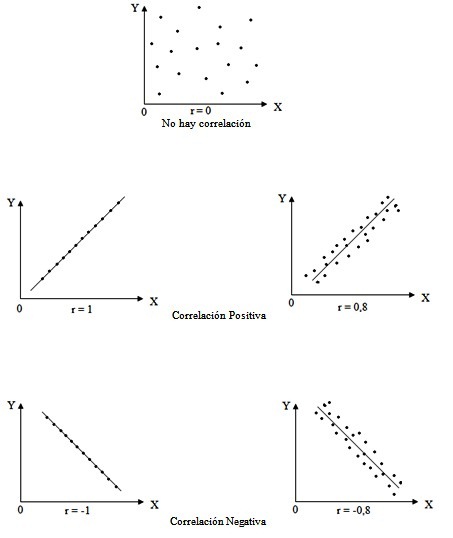



 n = número de datos.
n = número de datos.

 Siendo Cov (X,Y) la covarianza entre las series temporales X e Y, y σX e σY las desviaciones estándar de X e Y.
Siendo Cov (X,Y) la covarianza entre las series temporales X e Y, y σX e σY las desviaciones estándar de X e Y. Los datos se muestran como un conjunto de puntos, cada uno con el valor de una variable que determina la posición en el eje horizontal y el valor de la otra variable determinado por la posición en el eje vertical.[1] Un diagrama de dispersión se llama también gráfico de dispersión.
Los datos se muestran como un conjunto de puntos, cada uno con el valor de una variable que determina la posición en el eje horizontal y el valor de la otra variable determinado por la posición en el eje vertical.[1] Un diagrama de dispersión se llama también gráfico de dispersión.